Learning Analytics: Theory-Free Zone?
Following my summary of the MOOC Research Initiative (MRI) conference, let me pick up on an important conversation that emerged. Are the analytics beginning to run on MOOCs (which are of course just one obvious place to run them, among many) moving education into a POST-THEORY state? Michael Feldstein, Mike Caulfield, Bonnie Stewart, Martin Weller and Matt Crosslin (probably others) have blogged on this post-MRI, variously sounding warnings about the depersonalisation of learning if we don’t resist the machines (and the companies selling them), Big Data rhetoric, and nerdy computer scientists who know little about learning (ok, I paraphrase!).
For learning analytics, this is a pretty Big Question. Are we about to destroy the very thing we love by trying to measure it with dumb-downed blunt instruments? Are we inventing high tech versions of the high stakes exams we all love to hate for masquerading as proxies for real learning? Particularly when it comes to MOOCs, when skilled educators are thin on the ground, what are we going to do about authentic assessment of deep learning, when there are no dedicated mentors to give personal attention to each learner, to affirm and challenge them, and carefully feed back through rich, in-depth conversations (that’s what happens in all schools and universities, right? 😉
22 Dec update: gotta drop in this tweet from @Wiswijzer2 (“on the difference between knowing and measuring“)

While the word “Theory” may be a dirty word for Big Data junkies, it’s not for academics I hope, nor reflective practitioners. But Theory must earn its value, not be left as an accepted common good. I think it also soon crosses over into Values, and Assumptions, and to claim that we are post-Values or post-Assumptions clarifies things I think: dangerous nonsense. However, as I propose below, we may already be seeing Theory-free, useful analytics…
As an opener, here’s John Behrens at my LAK13 educational data scientist panel:


So here goes…
All formal classification schemes distort reality
The effect that a formal classification scheme can have on the phenomenon it claims to describe is well known:
“accounting tools […] do not simply aid the measurement of economic activity, they shape the reality they measure”
Du Gay, P. and Pryke, M. (2002) Cultural Economy: Cultural Analysis and Commercial Life. Sage, London. pp. 12-13
In their deconstruction of the ways in which categorisation schemes gradually become invisible, as they embed into information infrastructures, Bowker and Star observe:
“Classification systems provide both a warrant and a tool for forgetting […] what to forget and how to forget it […] The argument comes down to asking not only what gets coded in but what gets coded out of a given scheme.”
Bowker, G. C. and Star, L. S. (1999). Sorting Things Out: Classification and Its Consequences. MIT Press, Cambridge, MA, pp. 277, 278, 281
Maps are not neutral
Sometimes mapping is held up as a way to avoid formal classification schemes. I think in some people’s minds, it’s something to do with the greater expressiveness that spatial representations have compared to the boring tables or taxonomising trees that they associate with classification schemes. “Mapping the terrain” invokes notions of simply painting what you see without judgement.
That may work to some degree for mapping spatial landscapes, but of course, a map is just another way to systematically distort reality for a particular purpose, and very useful it is too when done well, foregrounding information needed for a particular use-context, and hiding irrelevant details. When it comes to visualizing abstract information onto two or more dimensions, then clearly, many more decisions have been taken by the cartographer, and those who wrote the software. No lens is clean.
Data does not ‘speak for itself’
You are only looking at data because an unknown cloud of people have made a whole load of decisions that have finally delivered that data to your screen. Data requires humans to form it, and humans to interpret it.
danah boyd and Kate Crawford have helpfully unpacked six ‘provocations’ for big data:
boyd, d. and Crawford K. (2011) Six Provocations for Big Data. A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society. Oxford Internet Institute: Oxford, UK.
So when we talk about learning analytics, we should be walking in eyes wide open, bringing all of the above into the conversation. Any notion of analytics that does not do this is at best naive, and at worst unethical. If we take Doug Clow’s diagram of a basic analytics cycle (slide 5), my annotations hopefully make clear that many human judgements must be made at each stage:
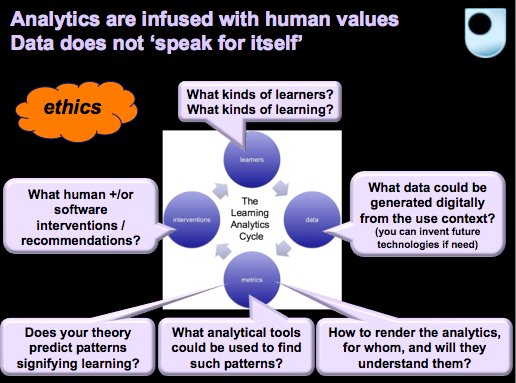
Governing algorithms
We see from the huge literature on ethics in ICT, the growing concern about governing algorithms, and emerging forums such as code acts in education, that the algorithms weaving through our lives must be critically deconstructed.
In one scenario (slide 77) I envisaged, I imagined the burden of knowledge that predictive analytics may bring in the future — the system didn’t actually make the decision for you, but did the information make it a harder decision?

However, Naomi Jeffery passed me a chilling example recently showing how an interview-shortlisting algorithm was carefully validated against human judgements — the only problem was that it faithfully embodied the institutional racism which had crept into faculty decisioning (BMJ pdf article).
Theory considered redundant
The infectious meme behind Chris Andersen’s End of Theory Wired piece was that Google has now rendered ‘theory’ dead, through the power of behavioural statistics and predictive algorithms. Mike Caulfield helpfully critiques this in terms of its limitations for designing learning interventions, arguing that you have to understand why something has happened in order to make an appropriate intervention. Maybe, maybe not. Consider the following — I think we are beginning to see something of Andersen’s vision coming true, and it’s not intrinsically bad.
Theory-free predictive modelling. Some predictive modelling in learning analytics has already entered what I would say is a theory-free zone. John Campbell’s PhD (underpinning Signals) showed that it is indeed possible to predict student failure without a theory of learning, purely by selecting the right variables from student demographics, grade history and usage of the online platform. NO THEORY here. But I’d welcome the Signals team’s comments on the implicit theory, pedagogy or assessment that lies behind the tips given to students. Again, it may be simply codifying educators’ craft knowledge and practice that drives these (not to be devalued in any way) — but not “theory” in any academic sense.
Theory-free student recommendations. Or to take another example, when MOOC students fail but then subsequently pass a test, in principle, machine learning techniques can track those behaviours which are correlated with subsequent success, so that automated interventions/recommendations can be made, again, purely on the basis of behavioural statistics, not a theory of learning. I don’t think that’s happening as a real time service yet anywhere, more offline lab analysis (seeking a pointer here – I recall Daphne Koller talking about this).
Theory-free social network analysis. I recently generated my social graph from LinkedIn, which I found to be an accurate and aesthetically pleasing mirror of my different professional worlds. If this was a visual analytic reflected back to me mid-way through a course, that might well give me pause for thought. What this does not do is give me any clue as to what to do about improving my social capital. If I had a view which wasn’t ego-centric, placing me in the middle, but showed me out on the edge of a cohort, that might well lead me to reflect differently. We’ll return to this shortly.
Do these examples fill you with excitement, and/or make you feel uncomfortable? Do these exemplify the “death of theory”?
They show the value and power of data-driven, algorithmic techniques, which leverage the power of finding patterns in large numbers of users and their activity. They are in no sense neutral, foregrounding certain values and assumptions, but they do not have an explicit ‘theory of learning’. Statisticians are very strong on understanding the assumptions that legitimise the use of a given approach: this is a great ‘middle space‘ area to explore — do the statistical approaches behind analytics make assumptions about learners’ similarity or continuity of behaviour that learning scientists support or challenge?
Next, we might ask: if the above impressive examples are possible with no formal educational theory, how much better can we do once we do bring it in?
Theory-based analytics?
So far, I’ve only talked about how we can’t escape values and assumptions in the socio-technical infrastructure that delivers analytics. What’s the relationship with theory?
Specifically in education, what about epistemology, pedagogy, and assessment regimes? Furious debates rage within education about how one may assess learning with integrity, at scale, quite apart from any digital technology. So in one paper we unpacked how we think these relate to learning analytics technologies. To jump to the end, we concluded:
“We have gone beyond “our learning analytics are our pedagogy” [6], arguing that they embody epistemological assumptions, and they perpetuate assessment regimes. Moreover, as with any tool, it is not only the design of the tool, but the way in which it is wielded in context, that defines its value.”
If we return to the SNA example, whether or not changing my behaviour makes sense for my learning is where SNA engages with epistemology, pedagogy and assessment regimes. Or in professional workplace learning, less tied to such formal academic concerns, notions of social capital, networked learning or communities of practice is where ‘theory’ may need to enter the conversation. The affordances of visualizations is therefore a key area for critique. The implicit message of a social network view showing me on the edge is that I should try to score higher on certain SNA metrics: I should try to be more densely connected; I should try to be a broker between two sub-communities I care about; I should forge ties with other key people. But what if creative innovators are the ones who resolutely stay on the edge? The ones who do not use the same tags as others? The ones who share ideas between strangely different communities? What if the stats show that non-social learners score at least as well in final assessments on this course?
At the LAK11 conference in Banff, I spoke on the role of theory in analytics, identifying a range of roles it could play — click through to see:

- If “post theory” is supposed to connote that data, algorithms and visualizations are finally liberating us from the perils of human bias, this is clearly nonsense. This does not stand up to any scrutiny, when you dig beneath how data comes to be collected, how algorithms are coded, and how visualizations are generated. When machines make decisions about those things, the waters will be muddy, but neutral they will never be.
- Some analytics are already possible with no formal educational theory. This gives us pause for thought indeed, and may make us feel uncomfortable, but this is all part of the shift that education and learning sciences are about to undergo, analogous to other fields who have shifted to a data-driven paradigm.
- Bottom-up mining of patterns may reveal phenomena that nobody was predicting based on formal theory, and to which we are therefore blinded. It will be an exciting moment when an unexpected pattern in the data, discovered by an algorithm as an apparent anomaly, leads to a theoretical breakthrough.
- “Theory” really means how we think the world works, which assumptions are being made, and ultimately, which values drive our notion of ‘good’ (if we’re interested in helping people learn and grow). Theory can be opaque to outsiders, but the language of assumptions and values could provide common ground for many stakeholders to gather round: educators, statisticians, data miners, visualization designers…
- We might argue that while adolescent analytics will simply visualize patterns and leave the learner or educator to make sense of them, grown-up analytics will go further and give clues as to whether these are strong or weak patterns, and what to do about them. And that requires a theory of some sort about how the world works — but for the first time, a theory which we can now validate at scale in unprecedented ways.
I am sure that many others have been thinking more deeply than this about the role of theory in data-intensive fields. We must be able to learn from the reflections of researchers in, for instance, biology and theoretical physics, whose work now depends on the use of massive datasets via new kinds of tools. And while there is (presumably?) something special about learning, which differentiates it from the study of proteins and quarks, where exactly do the analogies with these fields break down?
Good challenging piece. After 30 years of teaching and using technology in learning, I’d say that your analysis also arguably applies to ‘teaching’ in general, especially in HE. Given the paucity of actual reading, research, knowledge and training in ‘learning theory’ by HE teachers and the still central position of the ‘lecture’ as its core pedagogic device, teaching, I’d argue, is also, largely a theory-free zone. What attempts at data and algorithm-driven systems attempt is to capture good theory, so that is is scalable at low cost. We have seen this work in Google and in recommendation engines and to a lesser extent in predictive analytics. (Nate Silver’s book The Signal and the Noise gives a pretty fair account of things as they are.) But I would argue that some of the data- and algorithm-driven people I’m working with really are well read on learning theory and do care about the theory they embody into their approaches. In fact, the very act of designing data and algorithm approaches forces you into thinking deeply about such theory, and not just deliveing the next set of lectures. However, you have given us a good warning shot across the bows of the big data evangelists who see it as a battering ram, rather than a way of automating good teaching (and more importantly learning) theory and practice. In that sense I like your distinction between adolescent analytics and grown-up analytics. Many of those involved in this work I’d class as grown-up.
Developed this line a bit further in this talk…
http://people.kmi.open.ac.uk/sbs/2014/05/how-do-learning-analytics-act-in-education/
Dec 19th, 2013 at 9:14 pm
[…] Bonnie Stewart, The post-MOOC-hype landscape: What’s really next? Mike Caulfield, Short notes on the absence of theory Martin Weller, The iceland of Dallas Mike Feldstein, Why big data mostly can’t help improve teaching Simon Buckingham Shum, Learning analytics: Theory-free zone? […]
May 9th, 2014 at 3:52 pm
[…] 2.00 Professor Simon Buckingham Shum, Open University, Assoc. Director (Technology) at the Knowledge Media Institute, co-founder of the Society for Learning Analytics Research, and FutureLearn advisor. Simon will examine how analytics embody educational worldviews. […]
Jan 13th, 2016 at 2:40 pm
[…] version of education technology; the possibility of such a thing is something that has been widely debated in recent years within ed-tech and learning analytics circles. If, as some like […]